2년 정도 OS X를 개발환경으로 사용했더니, 얼마 전 이직한 회사의 Windows 10 환경이 낯설게만 느껴졌다. Shell이 제일 불편했고, 각종 오픈소스 문서에 나오는 설정을 따라 하는데 Windows의 경우 설명이 친절하지 않은 경우가 많았다.
집에서는 Mac을 사용하다 보니 매번 다른 환경이 적응 안되기도 하고 남들 다 윈도우 PC 쓰는데 혼자만 Mac 사달라고 할 수도 없고 git bash로 근근이 버티고 있었는데, Windows 10에 Windows Subsystem for Linux(WSL)라는 반가운 기능이 생긴 걸 알게 되어 그 방법에 관해 설명한다. (아마도 윈도우는 공인인증서 쓸 때만 쓰다 보니 혼자만 몰랐던 듯..)
설치하기
윈도우 빌드 정보 확인
WSL 기능을 사용하려면 Windows 10의 빌드 버전이 14316 이상이어야 한다. 버전 확인은 [설정] -> [정보] -> [OS 빌드]를 확인하자.
개발자 모드 설정
[설정] -> [업데이트 및 보안] -> [개발자용] -> [개발자 모드] 선택
윈도우 기능 켜기
[제어판] -> 프로그램 및 기능 -> [Windows 기능 켜기/끄기] -> [Linux용 Windows 하위 시스템] 체크 후 재부팅
pyenv install 3.6.4 # python 3.6.4 버전 설치 pyenv virtualenv 3.6.4 myenv # 3.6.4 버전을 기반으로 myenv라는 가상환경 생성 pyenv shell myenv # myenv라는 가상환경 activate pyenv versions # 설치된 python 버전 목록 출력
autoenv
autoenv까지 설치하면 유용한데, 특정 프로젝트 디렉터리에 진입하면 자동으로 스크립트를 실행시킬 수 있기 때문이다. 이 기능을 활용해 pyenv shell xxxenv와 같이 특정 python 환경을 자동으로 activate 할 수 있다.
원하는 디렉터리에 .env 파일을 만들고 스크립트를 적어놓으면 그 디렉터리 접근 시 자동으로 스크립트가 실행된다. .env 파일은 종종 다른 라이브러리의 환경설정 파일과 이름이 겹친다. 그래서 나는 .autoenv로 이름을 바꾸어 사용하는데 그러려면 ~/.zshrc 파일에 추가한다.
1
export AUTOENV_ENV_FILENAME=".autoenv"
위에 추가한 source ~/.autoenv/activate.sh 보다 위에 추가해야 한다.
처음 디렉터리에 접근 시 1번은 확인하는 구문이 나온다. y를 누르면 지정한 스크립트가 실행되는 것을 볼 수 있다.
1 2 3 4 5 6 7 8 9 10 11 12
$ cd blog autoenv: autoenv: WARNING: autoenv: This is the first time you are about to source /mnt/d/work/documents/blog/.autoenv: autoenv: autoenv: --- (begin contents) --------------------------------------- autoenv: echo "hello"$ autoenv: autoenv: --- (end contents) ----------------------------------------- autoenv: autoenv: Are you sure you want to allow this? (y/N) y hello
Node.js npm
역시 apt-get이 있으니 간편하다. 아래 스크립트의 setup_x.x 부분에 설치하고 싶은 버전을 적으면 된다.
Django는 우리가 웹사이트를 구축하기 쉽도록 도와주는 파워풀한 웹 프레임워크이다. Django는 개발 시 사용할 수 있는 간단한 웹서버를 탑재하고 있어, 로컬에서 코드를 테스트해 볼 수 있다. 그러나 실제 운영 서버에서 사용하거나 더 향상된 보안을 위해서는 웹서버가 필요하다.
이번 가이드에서는 운영 서버 환경에 Django Virtual 환경을 어떻게 설치/구성하는지 살펴본다. Apache 서버를 이용해 프론트 애플리케이션을 핸들링하고 클라이언트의 요청을 Django app에 보내는 방법을 살펴볼 것이고, 이것은 mod_wsgi라는 Apache 모듈을 이용하여 Django와 Apache와의 커뮤니케이션이 가능하도록 설정할 것이다.
사전 지식 및 목표
이 가이드에서는 Ubuntu 14.04 서버를 이용할 것이고 non-root 유저를 사용하여 sudo 권한으로 설정할 것이다. Ubuntu 서버는 Azure나 AWS를 이용해 쉽게 생성 가능하다. 우리는 Django를 python 가상환경을 사용하여 설치할것이다. 가상환경은 우리의 프로젝트에 필요한 패키지를 격리된 환경에 설치 할 수 있도록 도와준다.
Django app을 Apache 인터페이스에 설정하기 위해 mod_wsgi라는 Apache 모듈이 필요하다.
Ubuntu repository를 이용한 패키지 설치
첫 단계로 우리는 필요한 것들을 Ubuntu repository를 이용해 다운로드하고 설치 할 것이다. Apache web Server, Apache를 Django App과 연결하기 위한mod_wsgi 모듈 그리고 우리 프로젝트에 포함된 python 패키지를 다운로드하기 위한 패키지 매니저인 pip가 필요하다.
`myenv`는 임의로 정한 가상환경의 이름이다. 이 명령어로인해 anchvy 디렉터리 안에 `myenv`라는 디렉터리가 생성된다. 이 디렉터리안에는 우리가 사용할 python과 pip가 설치된다. 우리는 이것을 이용하여 격리된 python 환경에서 우리 프로젝트를 실행 할 수있다.
그럼 python 가상환경으로 들어가 보자. ```bash source myenv/bin/activate
가상환경으로 진입하면 쉘의 앞부분에 가상환경이름이 표시된다.
1
(myenv) crynut84@anchovy-web:~/anchovy$
python 패키지 설치
우리 프로젝트는 requirements.txt 파일에 python 패키지의 종속성이 표기 되어있다. 가상환경 내에서 이를 이용하여 패키지를 설치해 보자.
1
(myenv)$ pip install -r requirements.txt
pip는 requirements.txt에 기록된 패키지를 python 가상환경내에 설치 해 줄 것이다. 이를 확인하려면 myenv안의 폴더를 뒤져보면 된다.
프로젝트 설정 마무리
개발한 프로젝트를 운영환경(Production)에서 돌리려면 몇가지 설정을 해야한다. 디버깅을 위해 설정했던 기능을 꺼주어야하고, 프로젝트내에 포함된 스테틱 컨텐츠(css, jaavascript, image 등)를 한데모아 통합하는 일, 그리고 디비의 설정을 실제 디비로 바꿔주는 일등이 있다.
다음의 명령어로 프로젝트의 스테틱 파일을 한데 모을 수 있는데, 저 명령어를 수행하고 나면 settings.py의 STATIC_ROOT 경로로 파일이 모이게 된다. 왜 스테틱 파일을 모아야하는지는 다음 설명(Django static)을 참조한다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
python manage.py collectstatic ```
프로젝트의 `settings.py`를 열어(vi XXX/settings.py) DB설정을 실서버로 변경한다. (이부분은 향후 자동화하는 방법이 필요하다.)
그리고 pip를 통해 mysql에 접속하는 python 모듈인 mysqlclient를 설치한다.
1
pip install mysqlclient
이 경우 Azure Ubuntu에서 mysql_config: not found 오류가 발생한다 sudo apt-get install libmysqlclient-dev을 먼저 설치 후 다시 mysqlclient를 설치하면 된다.
DEBUG 모드가 아니므로 DEBUG 속성을 False로 수정하고, 모든 클라이언트 요청을 처리하기위해 settings.py의 ALLOWED_HOSTS 속성을 수정한다.
1 2
DEBUG = False ALLOWED_HOSTS = ['*']
Apache 설정
우리 Django 프로젝트를 Apache와 연결시키는 방법을 알아보자. Apache는 클라이언트의 요청을 WSGI 포맷으로 변경하여 Django 어플리케이션으로 전달해야하는데 이 작업을 mod_wsgi 모듈이 담당한다. 이 설정은 아까 설치할때 이미 활성화되어있다. 위 경로의 apache 설정을 수정한다.
1
sudo vi /etc/apache2/sites-available/000-default.conf
우선 static file의 경로 설정을 한다. 그 다음 wsgi 경로 설정. 그 후 python 경로설정과 virtual 환경 설정을 한다.
우리가 개발한 프로젝트를 운영 서버로 배포하다 보면 static 파일을 한데 모으는 python manage.py collectstatic이란 명령어를 접하게된다. collectstatic 명령어는 Django 프로젝트의 여러 app에서 사용하는 스테틱 파일을 한 곳(경로)으로 모아주는 역할을 한다.(물리적으로 파일을 copy 한다는 뜻이다)
웹 서버와 웹 어플리케이션
Django를 이용하여 웹 애플리케이션 개발할 때 Django에 내장된 경량의 웹서버를 사용하게 된다. 하지만 공식문서에도 경고하고 있는것처럼 이것은 실제 웹서버가 아니므로 Production 환경에서는 사용해서는 안 된다.
don’t use this server in anything resembling a production environment. It’s intended only for use while developing. (We’re in the business of making Web frameworks, not Web servers.)
프로덕션 환경과 유사한 상황에서는 사용하면 안 된다. 오직 개발 중에만 사용해라.(이건 웹 프레임워크를 만들기 위한 것이지 웹서버가 아니다.)
그렇다! runserver로 사용하는 개발용 서버는 서버가 아니다. 실제 Production 환경에서는 Apache나 Nginx와 같은 웹서버를 사용해야 한다. 즉 사용자의 요청(Request)이 들어오면 웹서버가 받아서 적절한 처리 후에 웹 애플리케이션에 넘겨주고 웹 애플리케이션은 우리가 작성한 로직에 따라 적절한 처리 후에 웹서버에 돌려주어 사용자에게 응답(Response)하는 것이다.
이것을 간단하게 도식화하면 위의 그림과 같은데 웹서버와 웹 애플리케이션 사이에는 WSGI(Web Server Gateway Interface)라는 규약으로 통신하게 된다.
스테틱 파일을 모으는 이유?
HTTP 프로토콜을 이용하여 단순히 파일을 응답하는 처리는 웹서버가 잘하는 일이다. 사용자의 요청의 URL을 해석하여 서버 내의 물리적인 위치의 파일을 찾아 HTTP 응답으로 돌려주는 단순한 작업이기 때문이다. 그에 반해 웹 애플리케이션 동적인 데이터를 처리하기 위해 만들어졌다. 예를 들어 로그인한 사용자마다 카트의 내용이 동적으로 변하여 다르게 보인다든가 하는 처리를 말하는 것이다.
CSS, Javascript, image 파일들로 이루어진 static 파일을 웹어플리케이션인 Django가 처리하기에는 너무 비효율적이다. 웹서버에서 웹 애플리케이션으로 요청을 전달하는 데는 WSGI라는 변환과정을 거치며 이것은 자원을 소모하는 일이고, 굳이 웹서버도 할 수 있는 일을 웹 애플리케이션에서 할 필요가 없는 것이다.
그래서 Django에서는 Production에서의 static 파일을 처리하는 기능을 담고있지 않다.
개발할 때 보니까 되던데?
Django 개발할 때는 static 파일이 잘 전송되는 것을 볼 수 있다. 이것은 INSTALLED_APPS의 django.contrib.staticfiles이라는 모듈이 담당하고 있으며, 그마저도 settings.py의 DEBUG 속성을 False로 바꾸면 동작하지 않게된다.
이때부터는 static 파일의 처리는 웹서버가 담당하게 되는 것이다. 아파치 설정 중에도 static 파일의 경로를 정의하는 설정이 포함되는 것을 알 수 있다.
스테틱관련 설정
Django 공식 문서를 보면 settings.py에 정의 할 수 있는 static 관련 설정이 나온다.
STATIC_ROOT
STATIC_URL
STATICFILES_DIRS
STATIC_ROOT
실 서버 배포 시 static 파일을 collectstatic 하기위한 절대 경로이다. 기본 값은 None이며 다음과 같이 설정할 수 있다.
1
STATIC_ROOT = "/var/www/example.com/static/"
staticfiles contrib app이 활성화 되었을 때(기본적으로 Django 프로젝트를 생성하면 INSTALLED_APPS에 포함) ‘collectstatic’ 콘솔 명령어를 수행하면 해당 디렉터리로 static 파일들이 모인다.
STATIC_URL
URL로써 static 파일의 위치를 가르킬 때 사용하는 위치이다. 마찬가지로 기본값은 None이며 아래와 같이 설정한다.
앱에 포함된 기본 static 파일의 경로는 {APP_NAME}/static이다. manage.py의 커맨드 명령어인 findstatic을 수행하면 우리가 찾고자 하는 static 파일의 풀 경로를 보여준다. 이때 우선순위는 기본 앱의 경로보다 STATICFILES_DIRS에 명시된 경로가 먼저 사용된다.
Prefixes
STATICFILES_DIRS 지정 시 Optional 속성으로 Prefix를 넣을 수 있다.
예를 들어위처럼 downlaods라는 prefix를 넣으면 어떻게 될까? 해당경로에 있는 파일들은 collectstatic 명령을 내렸을때 STATIC_ROOT에서 지정한 폴더 하위에 downloads라는 폴더를 만들어 모이게 된다. 당연하게도 실제 제공되는 URL도 STATIC_ROOT에서 지정한 경로에 downloads를 붙여 제공하게 된다.
elasticsearch는 lucene 기반의 실시간 검색을 제공하는 분산 검색엔진이다. 검색 기능뿐만 아니라 강력한 집계 기능을 제공해 실시간 분석 엔진으로도 활용 가능하며, 데이터를 저장할 수 있어 NoSQL 저장소로도 활용할 수 있다. 넷플릭스(Netflix), 깃허브(Github), 위키피디아(Wikipedia) 등 잘 알려진 사이트에서도 검색, 로그, 분석 등 다양한 용도로 클러스터를 운영하고 있다.
이 문서는 elasticsearch v5.0을 Azure 가상머신(Ubuntu 16.04 LTS) 버전에 설치하기 위한 가이드이다.
elasticsearch는 Java로 구현되어있으며, 구동을 위해서는 Java 8이 필요한데 Oracle’s Java와 openJDK만을 지원한다. 또한 elasticsearch를 분산서버에 구축할 경우 모든 node는 같은 버전의 Java를 사용해야한다.
Java 버전은 1.8.0_73 또는 그 이상을 권장한다. 다른 버전의 자바를 설치 할 경우 구동이 안될 수 있다. elasticsearch는 JAVA_HOME 환경변수에 지정된 Java version을 사용한다.
Ubuntu에 Java 8 설치
apt-get을 사용한 설치방법이 가장 쉽다. apt-get은 package의 repository에서 package를 검색/설치할 수 있는 패키지매니저이다. java8은 azure ubuntu의 기본저장된 reposigory에서는 설치할 수 없으므로 webupd8team의 Java PPA repository를 먼저 추가 후 설치한다.
elasticsearch v5.0부터 메모리 설정이 /etc/init.d/elasticsearch에서 /etc/elasticsaerch/jvm.options로 옮겨졌다.
1 2 3 4 5
참고: For the current version of elastic (5.0) you can configure jvm startup options in the jvm.options file usually located under directory /etc/elasticsearch/jvm.options:
사용자명과 이메일을 설정하였다. git은 commit할 때 이 정보를 사용한다. --global 옵션에서 알 수 있듯이 시스템의 사용자에게 적용되는 옵션이다. --global 옵션을 빼고 각 repository 별로 설정 할 수 도 있다.
git config --list로 모든 설정을 확일 할 수있고. git config user.name처럼 특정 설정을 확인 할 수도 있다.
git init, git clone
git repository를 만드는데는 2가지 방법이있다. 하나는 내 로컬의 디렉터리를 git repository로 만드는 것이고 원하는 디렉터리에서 아래 명령을 실행하기만 하면 된다.
1
$ git init
이 명령을 실행하면 .git 이라는 디렉터리가 만들어지는데 이안에 있는 내용이 git이 repository를 관리하기 위한 파일이고 이후의 저장소 내부의 변화를 감지하기 시작한다. 그리고 git init 명령을 실행한 디렉터리를 working directory라고 부른다.
다른 하나는 이미 만들어져 있는 git repository를 clone하는 것이다.
1
$ git clone [url]
clone 명령어를 이용해 가져 올 수 있는데 url은 repository의 주소이다. github를 기준으로 다음과 같이 clone 할 수 있는 url을 제공해 준다.
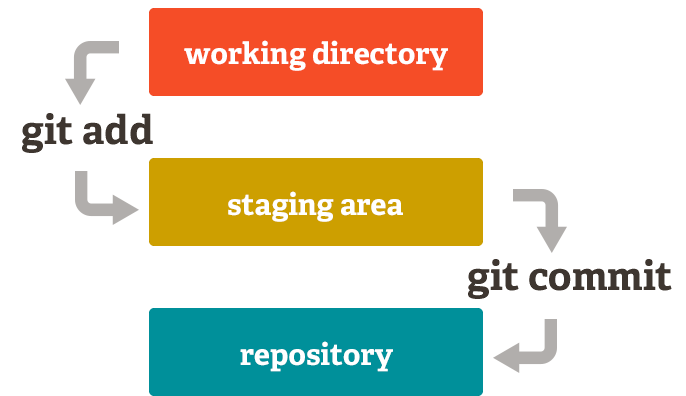
a.txt라는 빈 텍스트 파일을 생성한 후 git status 명령어로 확인 해보면 아래와 같이 Untracked files 목록에 a.txt 파일을 볼 수 있다. 이 상태를 이해하기 위해서는 먼저 git의 working directory에 있는 파일의 라이프사이클에 대해 알 필요가 있다.
위의 그림에서 알 수 있듯이 파일은 관리되는 파일(Tracked)과 관리되지 않는 파일(Untracked)로 나뉜다.
Tracked 파일의 상태를 감시한다. 파일의 상태를 아래 3가지로 분류하여 관리한다.
Unmodified 파일의 변경이 없는 상태
Modified 파일이 수정된 상태
Staged Modified 상태의 파일을 commit 하려면 Stated 상태로 만들어야한다.
Untracked 파일의 상태를 감시하지 않는다.
이제 앞서 추가한 a.txt 파일이 Untracked 상태인것이 이해 될 것이다. 우리가 처음으로 파일을 추가하면 Untracked 상태로 추가된다.
git add
그럼 a.txt파일을 git add 명령어로 추가해보자. git add [파일명]으로 추가 할 수 있다.
$ git add a.txt
이렇게 Untracked 상태인 파일을 add하면 Stated 상태가 된다. 앞서 설명했듯이 Staged 상태의 파일은 commit에 포함되는 대상이 된다.
1개의 파일(a.txt)가 commit 된것을 확인 할 수 있다. 다시 git status로 상태를 확인해보면 commit 할 것이 없으며 working directory도 클린하다고 알려준다.
1 2 3
$ git status On branch master nothing to commit, working directory clean
이 상태에서 a.txt 파일을 수정해 보자. 수정하면 자연스럽게 modified 상태로 바뀔 것 임을 예상 할 수 있다.
1 2 3 4 5 6 7 8 9 10
$ echo'파일 수정' > a.txt $ git status On branch master Changes not staged for commit: (use "git add <file>..." to update what will be committed) (use "git checkout -- <file>..." to discard changes in working directory)
**modified: a.txt**
no changes added to commit (use "git add" and/or "git commit -a")
이제 git add 명령을 실행하면 a.txt는 다시 Staged 상태가 되고, commit의 대상이 된다. 즉 git add명령은 Untracked 상태이거나 Modified 상태인 파일을 Staged 상태로 바꾸는 명령어이다.
Staged 상태에 대해 더 자세히 알아보기 위해 `git add’하고 파일을 한번 더 수정해 보자.
1 2 3 4 5 6 7 8 9 10 11 12 13
$ echo'파일을 한번 더 수정' > a.txt $ git status On branch master **Changes to be committed:** (use "git reset HEAD <file>..." to unstage)
modified: a.txt
**Changes not staged for commit:** (use "git add <file>..." to update what will be committed) (use "git checkout -- <file>..." to discard changes in working directory)
modified: a.txt
a.txt의 상태가 두개가 되었다. 어떻게 된 것일까? 이 개념이 아주 중요한데, Stated 상태라는 것은 git add할 당시의 파일을 스냅샷이라는 것이다. 위에 있는 Stated 상태의 a.txt의 내용은 git add를 했을 당시 내용인 ‘파일 수정’이라는 문구가 있을 것이고 UnStated 상태의 a.txt 파일에 내용은 ‘파일을 한번 더 수정’이라는 문구가 들어 있을 것이다. 만약 이 상태로 commit을 수행하면 Staged 상태의 내용인 ‘파일 수정’ 문구가 들어있는 a.txt의 스냅샷이 commit 된다.
마지막으로 수정한 정보까지 포함하여 commit 하고 싶다면 git add 명령으로 한번 더 a.txt를 추가 해 주면 된다.
추가로 일반적으로 프로젝트를 수행하면 여러 파일을 추가/수정 하는 일이 많을 텐데, 그런경우 git add *.js 나 git add . 같이 한번에 여러 파일을 add 하는 방법도 있다.
git diff
위의 예에서 보았듯이 Staged 상태라는 것은 git add 할 당시의 파일의 스냅샷이다. 그런데 개발을 하다보면 git add한 파일을 무심코 다시 수정하고 그냥 commit하는 실수가 있을 것 같다. git diff명령은 이럴 때 유용한 명령인데, Staging 영역(Stated된 스냅샷을 모아놓은 영역)과 Working Directory의 차이를 보여준다. 위의 예제에서 git diff 명령을 수행해 보자.
1 2 3 4 5 6 7 8
$ git diff diff --git a/a.txt b/a.txt index ecb3871..40efd75 100644 \--- a/a.txt +++ b/a.txt @@ -1 +1 @@ -파일 수정 +파일을 한번 더 수정
Staging 영역에는 ‘파일 수정’이라는 내용의 파일이 Working 영역에는 ‘파일을 한번 더 수정’이라는 내용의 파일이 들어있는 것을 볼 수 있다. commit을 수행하기 전에는 항상 git status로 내가 포함 할 파일의 목록이 정확히 포함 되었는지 확인 하고 git diff 명령으로 staging 영역과 working 영역의 차이가 없는지 살피는 습관을 들인다면 commit을 실수하는 일을 줄 일 수 있을 것이다.
추가로 Staged 상태와 이전 commit의 상태를 비교해 보려면 git diff --cached 옵션을 붙여서 실행하면 된다.
이전 상태의 commit에서 a.txt는 빈파일이었으니 아무것도 나오지 않았고 현재 Stated 상태의 a.txt는 ‘파일 수정’이라는 문구가 추가로 들어갔다는 것을 볼 수 있다.
git commit
드디어 git에서 가장 중요한 명령어 중 하나인 git commit 명령어를 소개 할 차례이다. commit은 하나의 작업단위(변경사항)를 local repository에 기록하는 것이다.
그럼 하나의 commit은 언제 만드는 것이 좋을까? 프로젝트를 수행함에 있어, 코드를 변경한다는 것은 어떠한 목적(요구사항)을 달성하기 위한 행위이다. 나는 이슈관리시스템(TFS)에서 하나의 Backlog item이나 Bug item을 할당 받으면 그것을 분석하여, 논리적으로 묶일 수 있는(혹은 다른 코드에 영향이 없을단위)로 쪼개서 하위 Task를 생성한다. 그리고 이 Task를 commit과 1:1로 맵핑 시킬 수 있도록 노력하는 편이다. 그렇기에 어떤 commit에는 100개의 파일이 추가/수정/삭제되어 있을 수도 있고, 어떤 commit에는 단하나의 파일만 수정되어 있을수도 있다. commit의 단위는 자유롭게 설정하여 사용 할 수 있기 때문에 어떻게 제한 할 지는 각 프로젝트의 상황이나 팀원간의 합의에 따라 적절하게 정하면 된다. 다만 commit을 작성하는데 참고가 될만한 글을 소개한다. 커밋 메시지에 대해라는 제목의 글인데 커밋메세지를 작성하는 방법에대해 토론한 내용을 정리한 글이다.
변경 사항에 따라 로직을 이해할 수 있는 수준의 단일 커밋 단위로 쪼개야 한다.
커밋 메세지를 작성하는 방법에서 커밋의 단위를 어떻게 가져가야 할지 예측해 볼 수 있을 것이다.
위의 예제를 계속 이어가기 위해 a.txt를 stating 영역으로 add하고 git status로 변경 사항을 확인한다.
1 2 3 4 5 6 7
$ git add a.txt $ git status On branch master Changes to be committed: (use "git reset HEAD <file>..." to unstage)
modified: a.txt
이 상태에서 git commit' 명령을 수행하면 commit 메세지를 적을 수 있는 text-editor가 실행된다.
!(github clone url)[https://crynut84.github.io/images/posts/basic-command-git/git-commit-editor.png]
이 editor는git config –global core.editor명령으로 변경 가능하다. editor를 실행하면 여러줄의 commit 메세지를 작성 할 수 있고, 한줄의 짧은 메세지로 commit 할 경우에는 위의 예제에서 실행 했듯이-m’ 옵션을 주어 짧은 commit을 실행 할 수도 있다.
1 2 3 4 5 6
$ git commit -m 'my commit message' [master ac05efa] my commit message 1 file changed, 1 insertion(+) $ git status On branch master nothing to commit, working directory clean
모든 변경사항을 commit한 후 git status명령으로 상태를 확인하면 위와같이 working directory가 깨끗하다는 메세지를 확인 할 수 있다. 모든 변경사항이 commit 된 것이다. 한번 commit한 사항은 local repository에 저장되기에 언제든 조회,복구 할 수 있다. 특별한 일이 없는 한 commit된 것은 날아가지 않는다.(remote server에 push한 경우에는 더더욱) 하지만 commit 하지 않은 것은 언제든 잃어 버릴 수 있다.
또한 위의 링크에서도 알 수 있듯이 우리는 commit 메세지 작성을 잘 해야한다. commit 메세지가 잘 작성된 경우에는 commit 메세지를 확인 하는 것만으로도 프로젝트의 히스토리를 파악 할 수 있다.
추가로 git add하지 않은 Working영역의 Tracked file을 모두 커밋하고자 할때에는 -a옵션을 사용한다.
1
git commit -a -m 'commit all tracked files'
-a 옵션을 사용경우 git은 Working영역의 파일을 stating 영역에 넣고, commit하는 것과 동일한 결과를 준다.
git reset
프로젝트 파일을 수정 할 때 어떠한 목적을 가지고(하나의 commit에 묶일 수 있도록) 파일을 수정하겠지만, 사람이 하는 일이 항상 마음 먹은대로되는 것은 아니다. a.txt파일을 수정하는 미션을 받고 수정하는 중에 b.txt파일을 추가 했다고 가정해 보자. 논리적으로 a.txt파일을 수정한것만 하나의 commit으로 묶어야한다면, a.txt 파일을 git add하여 Stating 영역에 넣고 commit 하면 된다. 그런데 실수로 b.txt파일도 Stating 영역에 들어갔다면 b.txt파일을 다시 working 영역으로 옮기는 방법이 필요하다.
이럴 때 ‘git reset’명령을 사용하면 된다. 실습을 위해 a.txt파일을 수정하고, b.txt파일을 새로 만들어 보자.
1 2 3 4 5 6 7 8 9 10
$ echo'modify a.txt file' > a.txt $ cat > b.txt $ git add * $ git status On branch master Changes to be committed: (use "git reset HEAD <file>..." to unstage)
modified: a.txt new file: b.txt
git add * 명령으로 모든 변경사항이 stating 영역에 포함되었다. 이 상태에서 commit하면 a.txt,b.txt두개의 파일이 commit 될 것이다. b.txt를 commit에서 제외하기 위해 아래와 같이 git reset 명령어를 수행해 보자.
1 2 3 4 5 6 7 8 9 10 11 12
$ git reset HEAD b.txt $ git status On branch master Changes to be committed: (use "git reset HEAD <file>..." to unstage)
modified: a.txt
Untracked files: (use "git add <file>..." to include in what will be committed)
b.txt
b.txt파일이 이전 상태로 돌아간 것을 확인 할 수 있다. 이처럼 git reset은 staging 영역에서 working 영역으로 되돌리는 역할을하고, 이를 이용해 commit이 포함될 파일을 조절 할 수 있다.
git rm
git이 관리하는(Tracked) 파일을 삭제하려면 어떻게 해야할까? 윈도우의 탐색기나 OSX의 Finder에서 파일을 삭제하거나 Terminal에서 RM 명령을 통해 삭제하면 된다.
위의 예제에서 working directory를 clean한 상태로 만들고 이어서 실습해 보자.(clean하게 하려면 commit 하면 된다.) a.txt파일만 있는 상황에서 terminal에서 rm 명령을 이용해 파일을 삭제한다.
1 2 3 4 5 6 7 8
$ rm a.txt $ git status On branch master Changes not staged for commit: (use "git add/rm <file>..." to update what will be committed) (use "git checkout -- <file>..." to discard changes in working directory)
deleted: a.txt
git은 파일의 삭제도 훌륭하게 추적하여 파일이 삭제되었음을 알려준다. 이 상태에서 git add명령어로 staging 영역에 추가하고 git commit하면 파일이 삭제된 스냅샷이 git repository에 저장 될 것이다.(앞서 배웠듯이 git -a commit명령으로 한번에 add+commit 할 수도 있다.)
git에서도 git rm이라는 명령어를 제공한다. 그냥 삭제해도 git이 알아서 인식하는데 왜 별도의 명령을 제공하는 것일까? 그냥 파일을 삭제해도 되지만 명령어는 몇가지 기능이 더 있다. 기본적으로 git rm 명령을 통해 파일을 삭제하면 파일을 삭제하고 자동으로 staging 영역으로 넣어준다.
1 2 3 4 5 6 7 8 9 10
$ git rm a.txt rm 'a.txt' $ ls -l total 0 $ git status On branch master Changes to be committed: (use "git reset HEAD <file>..." to unstage)
deleted: a.txt
그리고 이미 staging 영역으로 들어간 파일을 물리적으로 삭제하면 다음과 같이 2개의 상태를 가지게 된다.
1 2 3 4 5 6 7 8 9 10 11 12 13
$ git status On branch master Changes to be committed: (use "git reset HEAD <file>..." to unstage)
deleted: a.txt new file: b.txt
Changes not staged for commit: (use "git add/rm <file>..." to update what will be committed) (use "git checkout -- <file>..." to discard changes in working directory)
deleted: b.txt
b.txt가 새로 생성되었고, 삭제된 상태이다. git은 실수로 삭제하는 것을 막기위해서 이런 방법을 사용한다. git rm -f 옵션을 사용하면 바로 삭제처리도 가능하다.
git mv
git mv명령은 파일을 이동하는 명령이다. 이동이라는 것은 경로를 바꾼다는 뜻이며, 파일의 이름을 변경하는 행위와도 같다. 사용법도 아주 쉽다. 아래를 참조하자.
1 2 3 4 5 6 7
$ git mv a.txt c.txt $ git status On branch master Changes to be committed: (use "git reset HEAD <file>..." to unstage)
renamed: a.txt -> c.txt
git stash
TFS를 사용할 때 Shelve(보류)라는 기능을 유용하게 사용했었다. 이런 시나리오는 생각해보자. 어떤 Task를 할당받아 열심히 개발하는 중에 치명적인 버그가 발견되었다. 급하게 Hot Patch를 내놓아야 하는 상황에서 선택 할 수 있는 방법은 두가지이다.
하나는 현재 개발 중인 Task를 최대한 빨리 마무리하고, Hot Patch를 개발하는 방법이고, 또하나는 현재 진행하던 Task를 버리고(되돌리고) 급한 패치부터 개발하는 방법이다. Shelve는 이럴때 유용하게 사용 할 수 있는데 진행하던 Task를 보류시켜 놓고(어딘가에 저장) 이전 상태로 돌아가 Hot Patch를 만들어 checkin한 후 다시 보류된 작업을 꺼내와서 Task를 이어서 진행하는 방법이다.
git에도 git stash 명령어를 통해서 위와같은 시나리오에 대응 할 수 있다. 파일을 변경한 상태에서 (즉 워킹 디렉토리가 clean하지 않은 상태) git stash 명령을 사용하고 git staus명령으로 상태를 확인하면 아래와 같이 clean 한 상태가 된다. 이때 위의 시나리오처럼 다른 작업을 할 수 있는 것이다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
$ echo'change c.txt' > c.txt $ git status On branch master Changes not staged for commit: (use "git add <file>..." to update what will be committed) (use "git checkout -- <file>..." to discard changes in working directory)
modified: c.txt
no changes added to commit (use "git add" and/or "git commit -a") rynut84@ubuntu:~/work/git-test git stash Saved working directory and index state WIP on master: da3fe70 rename a.txt -> c.txt HEAD is now at da3fe70 rename a.txt -> c.txt crynut84@ubuntu:~/work/git-test$ git status On branch master nothing to commit, working directory clean
또한 stash 된 목록을 git stash list 명령으로 확인 할 수 있고, stashing 한 목록을 복원하려면, `git stash pop’ 명령을 이용하면 된다.
총 11가지 명령으로 git의 local repository를 다루는 방법을 배웠다. git이 가진 명령어는 지금 소개한것보다 훨씬 많지만(옵션까지 하면 더 많다) 이정도만 알아도 크게 불편한 점이 없었고, 더 자세한 기능은 그때그때 찾아보면서 쓰는 편이다.
Git is easy to learn and has a tiny footprint with lightning fast performance. It outclasses SCM tools like Subversion, CVS, Perforce, and ClearCase with features like cheap local branching, convenient staging areas, and multiple workflows.
배우기 쉽다는 것인데, 내가 처음 git을 배울 때는 다음과 같은 이유로 git이 무지 어려웠다.
git은 공식 사이트에 document가 굉장히 잘 만들어져 있다. 요즘 오픈소스는 대부분 document에 공을 들이는 것 같다. 고마운 분들이 번역해 놓은 한글판도 있다. 덕분에 특별히 책을 구입하지 않아도 배울 수 있다.
About 페이지에가보면 다음의 6가지 주제로 git을 소개하고 있다. 이 개념들이 기존 버전관리 시스템과 다른점이고 git을 사용하면서 얻을 수 있는 이점이다.
Branching and Merging
Small and Fast
Distributed
Data Assurance
Staging Area
Free and Open Source
Branching and Merging
git은 branch를 만드는데 부담이 없다. 그렇기 때문에 작은 단위의 기능으로 새 branch를 만들고 거기에 원하는 기능을 개발하거나, 실험하고 싶었던 기능을 실험 할 수 있다. 실험에 실패한다면? 그냥 branch를 버리는것으로 끝난다. 아무런 사이드 이펙트가 없다. 나는 TFS를 이용할 때 Branch를 만들때마다 부담스러웠다. 만드는 속도, 용량등 자주 만들기에는 너무 큰 부담이었고(덕분에 회사에 품의를 올려 256G SSD를 추가 구매 할 수 있었지만..) git을 사용하면 이런 고민을 조금은 덜 수 있다.
git은 branch를 만들어 구현하고, 구현한것을 commit 하고, 때때로 원래 branch로 돌아가 심각한 버그에대한 hotpatch를 만들 수 있다.
Small and Fast
branch를 만들고 merge하는 것이 부담스럽다면, 위와같은 작업을 할 수 없을 것이다. git은 거의 모든 작업을 local repository에서 수행하기 때문에 속도가 빠르다. 심지어 branch를 만들때도 remote server가 없어도 된다. 나중에 설명 하겠지만 git의 branch는 commit을 가르키는 포인터일 뿐이고, 그렇기 때문에 branch를 만드는 것 또한 빠르고 작은 용량으로 가능하다.
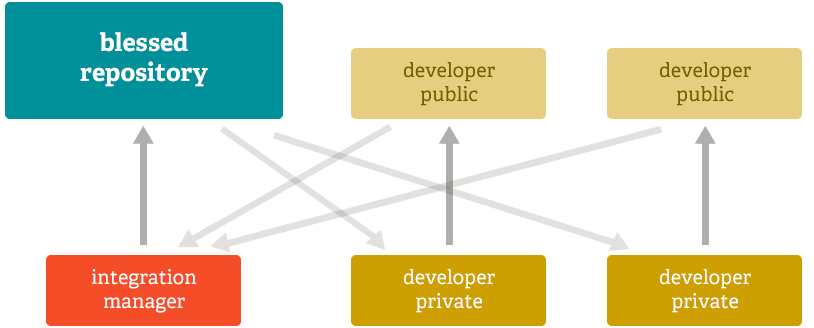
Distributed
분산 저장소는, 모든 사용자들이 온전한 git repository를 가진다는 의미이다. 내가 진행중인 프로젝트를 git을 이용하여 내려받는다면, 나는 remote repository와 동일한 repository를 내 local에 가져오게 된다. 이말을 바꿔말하면 단지 repository를 가져오는 것만으로 source, commit hitsotry등 모든 요소를 가져오게 된다는 말인다. 최악의 경우 remote server의 장애로 모든 데이터를 날렸다고 하더라도, 다른 사용자의 repository를 이용해 복원 할 수 있다는 말인다.
파일들은 working directory에 있다. 이 상태에서 a.txt파일을 수정하면 파일의 상태가 modified로 바뀌고, 예상하는 바와같이 commit을 하면 a.txt가 commit 될 것처럼 보인다. 하지만 git에서는 이렇게 동작하지 않는다. modiried 상태인 a.txt파일을 staging area로 등록해야만 commit에 포함된다. 즉 git은 stating area의 스냅샷을 commit으로 기록하는 것이다.
2010년 대학교 졸업 후 취업 할 생각은 안하고 빈둥거리고 있을 때, 지인의 소개로 모 회사의 SI 프로젝트에 프리랜서 자격으로 참여 할 수 있었다.
프리랜서이지만 나름 첫 출근날, 상콤한 마음으로 프로젝트 장소에 도착하여 간략하게 개발업무에 대한 설명을 듣고, 개발환경을 구축하려는 그때부터 나는 멘붕에 빠져버렸다.
사실 대학교 막 졸업한 내가 제대로 할 줄 아는것이 무었이 있었겠는가? 그냥 다 할 줄 안다고 패기있게 참여한 프로젝트였지만 첫 시작부터 예상치 못한 친구인 “버전 관리 시스템”을 만나게 되었다. 당시 그 업체에서는 Visual Source Safe라는 툴을 사용하고 있었는데, 버전 관리 시스템이라것을 거기서 처음 들은 나는 Source Safe에서 소스 받아가라는 PL의 말을 알아듣지 못 할 수 밖에..
대학에서 친구 몇 명과 조그만 프로젝트를 개발 할 때는 한명이 프로젝트를 생성하여 큰 틀을 만들고, 각자 역할에 나누어 개발 후 한 사람 PC에 옹기종기 모여 각자 개발 한 모듈을 USB에 담아 취합하는 작업을 했었다.
시스템이 복잡하면 할 수록 점점 소스를 취합하는것이 힘들어 질 것이다. 그리고 특정 파일을 3일전의 상태로 돌리고 싶다면 어떨까? 매일매일 소스를 백업하여 아래같이 해둔다면 어찌 해 볼 수 있겠지만 그마저도 없다면 오롯이 내 머릿속의 기억에만 의존해야하는 최악의 사태가 벌어 질 수 있다.
2015-06-01.zip
2015-06-02.zip
2015-06-03.zip
어떻게 이런 문제들을 해결 할 수 있을까?
버전 관리(Version Control)란?
개발자들은 자신의 머리가 그리 똑똑하지 못하는다는것을 오래전에 깨닫고 파일의 변화를 기록하는 시스템을 만들었으니 그게 버전관리 시스템이다.
아마 처음에는 자신의 컴퓨터에 있는 파일의 버전을 관리해주는 프로그램을 개발 했을 것이다. 내가 짠 소스코드의 변화를 시스템이 관리해주니 오늘 수정한 소스가 잘못된 것을 알았을 때 손쉽게 그 이전 버전이나, 특정 날짜에 작성한 버전으로 돌릴 수 있었을 것이다.
하지만, 소프트웨어는 여럿이 개발하는 경우가 많으므로, 내가 작성한 코드가 다른 사람에게도 보였으면 하는 생각이 들었을 것이고, 내 로컬에 변경사항을 기록하는 것이 아닌, 소스를 관리하는 서버에 변경사항을 기록하고, 각자 서버에서 소스를 받아서 사용할 수 있는 시스템을 만들었다. 그게 현재 사용하는 TFS, Source Safe, SVN, Subversion과 같은 프로그램이고 이것을 중앙 집중형 버전관리 시스템이라고 한다.
이 프로그램을 사용하면 다음과 같은 장점을 누릴 수 있다.
여러명의 개발자가 하나의 프로젝트를 동시에 개발 할 수 있다.
USB등으로 파일을 copy할 필요 없이 다른 사람이 개발한 소스코드를 내 컴퓨터에 받아 올 수 있다.
이 파일을 누가 언제 어떻게 수정했는지 이력을 볼 수 있다.
문제가 생겨 이전 버전으로 돌아가야하는 일이 생겼을 때 손쉽게 돌아 갈 수 있다.
Branch를 이용하여, 좀 더 안전하게 새 기능을 추가하고 Merge하여 통합 할 수 있다.
내가 A 기능을 개발하는 중에 급하게 Patch해야 할 버그가 생겼을 때도 잠시 A기능을 개발하지 전 상태로 돌려 버그를 수정하고, 다시 A기능을 개발하던 상태로 돌아 갈 수 있다.
하지만 TFS(중앙 집중형 버전관리 시스템)의 경우 모든 소스를 서버가 관리하기 때문에 다음과 같은 단점이 존재한다.
네트워크에 연결되어 있어야만 작업이 가능하다.(소스파일의 checkin, checkout시 서버에 접솝해야 한다.)
서버에 문제가 생기면 작업을 할 수 없다.
서버와의 통신이 지속적으로 이루어지기 때문에 네트워크가 느린경우 작업에도 영향을 미친다.
Branch하면 전체 소스를 다른 폴더에 받아오기 때문에 Branch가 많이 부담스러운 작업이다.
분산 버전 관리 시스템을 사용하면 앞서 말한 문제점을 해결 할 수 있다.
분산 버전 관리 시스템
중앙집중형 버전관리 시스템의 저장소(repository)가 server에만 있는것과 달리 분산 버전 관리 시스템에서 저장소는 모든 client가 저장소가 될 수 있다. 이게 무슨 말일까?
예를들어 TFS에서 get latest version을 통해 저장소에서 project를 가져온가고 생각해 보자. 그럼 저장소에서 사용자의 컴퓨터에 최신의 코드를 받아오게 된다. 분산 버전 관리 시스템의 경우 어떻까? server에서 저장소자체를 통채로 받아오게 된다. 이 말은 소스코드는 물론 그동안의 변경 이력까지 모든 정보를 가져와 로컬 컴퓨터 또한 완전한 저장소가 된다는 뜻이다.
이렇게 됨으로써 한번 저장소를 받아온 이후에 개발작업에서는 서버와는 별개로 자신의 로컬에서 진행하게 되고, 로컬이니 당연히 빠른 속도로 변경 할 수 있는 것이다. 만약 main.cs 파일의 지난 히스토리와 diff 하고 싶을 경우 TFS는 서버와의 통신을 통해 diff하는 반면 분산 버전 관리 시스템은 로컬에 있는 저장소에서 변경 이력을 찾아 diff해 준다.
이런 분산 버전 관리 시스템의 개념을 구현한 것이 git, Mercurial등이 있고, 나는 이제는 대새(?)로 자리잡은 git에 대해 설명 하려고한다. git은 리누즈 토발즈가 리눅스 커널의 버전관리를 위해 만들었다고 알려져 있다.
왜 git으로 바꿔야하나?
git은 어렵다. git을 만든 리누즈 토발즈도 한 인터뷰에서 이렇게 쓰기 어려운걸 누가 쓰리라곤 생각도 못했다.고 말했라고 한다. 특히나 CLI보다 GUI가 익숙한 닷넷 개발자는(닷넷개발자가 다 그렇다는 것이 아니다) 인터넷에 있는 git에 대한 사용법을 담은 자료를 보고, 버전 관리하는데 머가 이렇게 어려워?라는 생각을 가질 만하다.
우리 회사에서는 올해 초부터 시작해서 6개월동안 git을 사용하기 시작했는데, 내가 생각하는 장점은 다음과 같다.
Branch를 마음껏 할 수 있어, Backlog나 Bug 단위로 Branch를 만들어 개발하고 프로덕트를 release하는 Branch(master)는 clean하게 유지할 수 있다.(git workflow) -> 나는 이것이 git을 사용하는 가장 큰 benefit이라고 생각한다.
이 외에도 만약 이런 상태라면 git을 쓰자.
버전관리 시스템을 써본적이 없다. 하지만 이제부터 쓸 예정이다.
github 서비스를 remote 저장소로 사용 할 예정이다.
머릿속에 프로젝트에 대한 새로운 아이디어가 넘치는데 중앙의 source 이력을 망가뜨리지 않고 마구 실험해 보고 싶다.
오픈소스의 컨트리뷰터가 되고 싶을 때(많은 오픈소스가 git으로 진행되거나 전환하고 있다)
벌써 개발자로 살아온지 만 5년이 넘었다. 두번째 회사에 다니고 있지만, 두 회사 모두 닷넷 기술을 사용하여서, 닷넷은 나름 빠삭(?)하다 생각하지만 Java, Python, GO lang등 다른 언어나 기술 환경은 잘 모르는 처지가 되었다.
요즘 폴리글랏 프로그래머가 유행이라던데, 개인적으로 만드려고 했던 서비스를 만들면서, 닷넷을 벗어나 새로운 언어와 환경에서 만들기로 하고, 평소 관심을 가지고 있었던 node.js를 공부해 보기로 하였다.
node.js 개요
node.js는 서버사이드에서 동작하는 javascript이다. 브라우저에서 주로 사용되는 javascript가 어떻게 서버사이드에서 동작하는 것일까? 답은 바로 Google V8)(자바스크립트 엔진) 덕분이다. V8은 javascript를 JIT 컴파일하여 빠른 속도로 실행시켜주는 엔진이고, 크롬에서도 쓰이고 있으며, 오픈소스로 공개함으로써 브라우저의 전유물이었던 javascript를 외부에서 사용 할 수 있는 길을 열었다. node.js를 만든 Ryan Dahl(라이언달)도 반응성이 뛰어난 애플리케이션을 만들려고 하였을 때, V8을 써서 javascript의 비동기(async)를 이용한 node를 개발 할 수 있었다.
JSconf EU 2009 행사에서 라이언달(Ryan Dahl)이라는 개발자가 Node.js, Evented I/O for V8 Javascript라는 세션을 발표한다. 이 발표에서 라이언달은 node.js를 javascript를 이용해 I/O 프로그래밍을 할 수 있고, 개발에 있어 성능을 높이는데 집중했다고 한다.
node.js 설치
ubuntu 14.04 LTS(64bit)에 node.js 설치해보자.
apt-get(Advanced Packaging Tool)을 이용하여 설치
apt-get을 통해 설치하는것이 여러모로 편리하지만 한가지 주의 할 사항이 있다. 기본 repository에 있는 node.js 버전이 최신버전이 아닐 수 있다는 점이다. 오늘(2015-06-02) 기준으로 node.js 사이트에서 확인한 버전은 v0.12.4 버전이다. 그런 ubuntu 기본 repository에는 어떤 버전의 node.js가 있는지 확인 해 보자
1 2
sudo apt-get udpate sudo apt-cache policy nodejs
위의 명령을 통해 확인해 보면 다음과 같이 v0.10.25버전이 들어있는 것을 알 수 있다.
그럼 최신버전의 node.js를 apt-get을 통해 설치하려면 어떻게 해야할까?
기본적으로 apt-get을 사용하면 ubuntu에서 공식 운영하는 repository를 사용하여 다운로드 받게 된다. PPA(personal package archive)는 사설로 운영하는 저장소인데 node.js의 최신버전은 NodeSource라는 곳에서 관리한다.


























{kind=link}